Fetch Your Currently Playing Track Info From the Spotify Api
What song did I miss in the 2010s?
Use Spotify Web API and k-means clustering to find them out
Introduction
No one can deny that Spotify revolutionizes the whole music industry. But what many people don't know is that Spotify also provides a powerful Web API for free. After creating your developer account in Spotify, you can open this gate and play with massive information related to music. Today I am here to demonstrate how to play with Spotify Web API in Python.
Situation
I have my own playlist with 56 songs o nly. I am sure I miss a lot of good songs. But how can I identify what I miss? More importantly, how can I utilize my current playlist to find other songs that I probably like also? So a recommendation system is needed based on my current song list. But how to quantify songs that I love in my song list?
Let's begin!
First Step: Accessing Spotify Web API
First thing first, you need to set up everything in your Spotify account. Client ID and Client Secret are necessary. If you have not, just follow the "Set Up Your Account" Section under this link.
Once you set up an app on the Dashboard page, you will get the Client ID and Client Secret. These two are necessary for accessing Spotify API. AND DO NOT SHARE WITH OTHERS!

Spotify Web API is based on REST. So requests package is all we need. After getting Client ID and Client Secret, the next thing we need is the access token. You can post a request to Spotify and Spotify will return you the access token.
auth_response = requests.post("https://accounts.spotify.com/api/token", {
"grant_type": "client_credentials",
"client_id": CLIENT_ID,
"client_secret": CLIENT_SECRET,
}) auth_response_json = auth_response.json() access_token = auth_response_json["access_token"]
auth_response_json will be in a JSON format like below
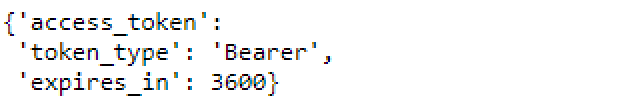
When we send any request to Spotify, we will add an extra header including this access_token.
headers = {"Authorization": f"Bearer {access_token}"} The basic URL of accessing API is https://api.spotify.com/v1/. The session following the URL is to select the type of API. For example, for an artist, the URL will be https://api.spotify.com/v1/artists; for a playlist, it will be https://api.spotify.com/v1/me/playlists. And then for each type of API, there will be different API calls. For further information, you can visit this link.

Second Step: My songs in my Spotify playlist
Now we are all set to have fun with Spotify API. The first question, what songs are in my playlist? To identify which playlist, you need to provide the ID of that playlist. The ID can be obtained if you click the three dots-> Share->Copy link to the playlist.
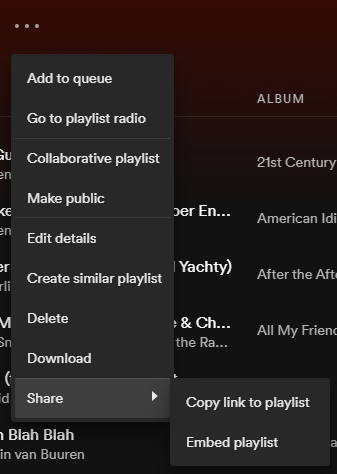
You will get a URL. A string after playlist/ is the ID of a playlist.

If we specifically get all songs within a playlist, you can do so as below:
requests.get("https://api.spotify.com/v1/playlists/YOUR_PLAYLIST_ID/tracks", headers=headers).json() However, one problem is that you will only get a maximum of 100 songs from Spotify API for each sending request.

As a result, if you have more than 100 songs on your playlist, then you need to include offset parameter and use for loop to get all song details.

But since my playlist only has 56 songs, so I am fine.
You will receive a long JSON. Each element in Item represents a song. It lists the details of a song, including song name, artists, and album name.
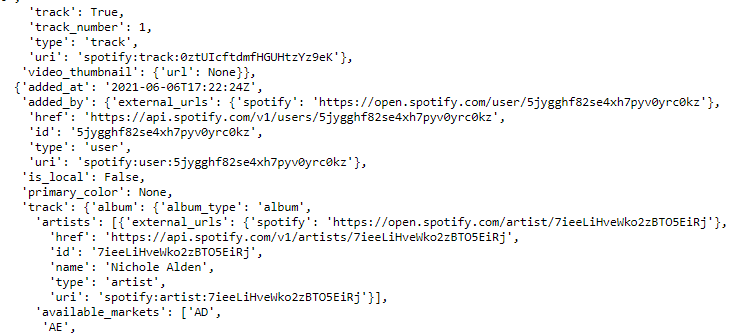
What we need for further steps is the ID of the song. But here we also get the song names and artists for just presentation.
Since we will send requests more than three times, I simply create a function as below (Link):
def send_request(send_type_,id_,remaining_ = ""):
return requests.get(BASE_URL + send_type_ +"/"+ id_ + "/"+remaining_, headers=headers).json() myPlaylist = send_request("playlists", YOUR_PLAYLIST_ID ,"tracks")
Third Step: Characteristics of a song
Time to find a way to describe what type of song I like. From the last step, we can obtain the unique ID for each song. In this stage, we can send a request using audio_featuresand including the ID as the parameter. For example:
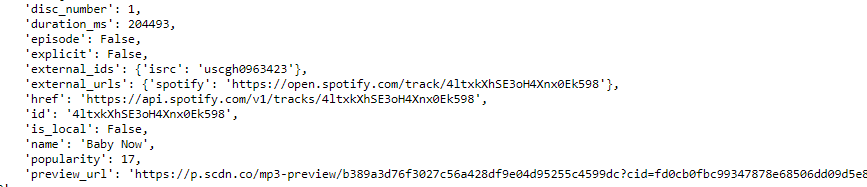
requests.get("https://api.spotify.com/v1/audio-features/4ltxkXhSE3oH4Xnx0Ek598/", headers=headers).json() This is what you will get, a JSON listing the characteristics of the song.
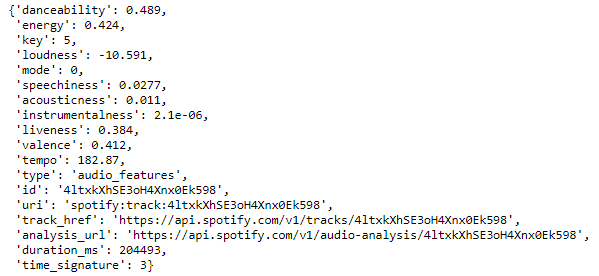
I will not explain what each character means here. If you are interested, go to this link to learn more.

Now we are almost done collecting all necessary information of songs in my playlist. The last step is to store all information in a dataframe.
# This is to get the song ID of a song
def get_id(dict_):
return dict_["track"]["id"] # This is to get all details of a song
def getSongDetail(trackID_):
# Get the audio feature of a song
audioFeatures = send_request("audio-features" , trackID_)
# Get the information of a song
songDetails = send_request("tracks", trackID_)
songName = songDetails["name"]
artists = songDetails["artists"]
artistsName = [x["name"] for x in artists]
# Combine all into a dict
return {**{"Song_Name": songName, "Artists": artistsName},**audioFeatures} mySongs = []
for song in myPlaylist["items"]:
mySongs.append(getSongDetail(get_id(song)))
mySongsDF = pd.DataFrame(mySongs)
Fourth Step: k-means clustering
(Here I assume you already know what k-means clustering is. If not, there are lots of material for the introduction. For example scikit-learn doc.)
So we will only need numeric variables for k-means clustering. Before performing clustering, standardization is also performed to align the scales for all numeric variables.
numeric_Variable = ["danceability", "energy", "loudness", "speechiness",
"acousticness", "instrumentalness", "liveness", "valence", "tempo","duration_ms"]
mySongsNumericDF = mySongsDF[numeric_Variable] # This is to standardize all numeric variables
mysongsScaler = StandardScaler().fit(mySongsNumericDF)
mysongsNormalizedDF = mysongsScaler.transform(mySongsNumericDF)
The Elbow method is used to find the optimal k.
# This is to return the sum of squared distances of samples to their closest cluster center.
def get_inertia(n_cluster_,df_):
return KMeans(n_clusters = n_cluster_, random_state= 42).fit(df_).inertia_ mySongSqDistance = []
for i in range(1,10):
mySongSqDistance.append(get_inertia(i,mysongsNormalizedDF)) plt.plot(range(1,10), mySongSqDistance, "rx-")
plt.show()
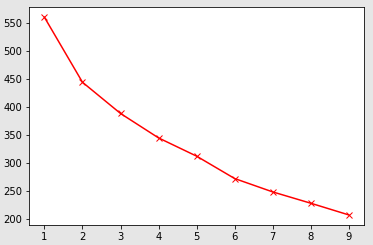
The elbow is not clear, but at least the drop from 1 to 2 is larger than from 2 onwards. So I take k =2 for the next step.
kMeansResult = KMeans(n_clusters = 2, random_state= 42).fit(mysongsNormalizedDF) First question: How many songs are in each cluster?
collections.Counter(kMeansResult.labels_)
# Counter({1: 18, 0: 38}) Second question: What songs are grouped in each cluster?
mySongsDF["kCluster"] = kMeansResult.labels_.tolist()
list(mySongsDF[mySongsDF["kCluster"]==1]["Song_Name"]) 
One interesting thing is that all my Cantonese songs are in this cluster.
Fifth Step: What song did I miss?
Now it's time to find what song did I miss.
I will use an existing song list and fit all songs into the trained k-means clustering. After clustering, I will further calculate the distance between each song and the centroid of the respective cluster.
The process of getting the characteristics of songs is the same as the previous. So the below focuses more on the k-means clustering part. The first is to standardize and then to predict the result.
# playlist_songsNumericDF is a dataframe for storing all numeric characteristics of all songs in the playlist # Below processes are to standardize all numeric variables and then predict the result. playlist_songsNormalizedDF = mysongsScaler.transform(playlist_songsNumericDF) playlist_songsPredict = kMeansResult.predict(playlist_songsNormalizedDF)
Below are the songs that are all predicted to be in cluster 1.

Then we calculate the distance between each song and its respective centroid of the cluster. Here we use Euclidean distance from numpy.
playlist_songsDF["Distance_to_Centroid"]=[np.linalg.norm(
result[0]-kMeansResult.cluster_centers_[result[1]])
for result in list(zip(playlist_songsNormalizedDF,
playlist_songsPredict))
] And the top five songs with the shortest distances to the centroid are:
list(playlist_songsDF[playlist_songsDF["kCluster"]==1].nsmallest(5,"Distance_to_Centroid")['Song_Name']) 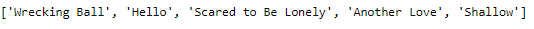
Final
Here I only demonstrate a simple example to utilize Spotify Web API. If you are interested in it, I suggest you visit the https://developer.spotify.com/ and discover other cool features Spotify provides you for free.
That's the end of this article and the whole Jupyter Notebook is already published on my GitHub (link).
See you next time.
Fetch Your Currently Playing Track Info From the Spotify Api
Source: https://towardsdatascience.com/what-song-did-i-miss-in-the-2010s-306ff6a061c5
0 Response to "Fetch Your Currently Playing Track Info From the Spotify Api"
ارسال یک نظر